I've built an app called Fork Freshness. In the process of building that app, I've learned some interesting things about how open source projects evolve over time.
What Is Fork Freshness?
A few years ago I needed to restore UPS shipping options to a Ruby gem called active_shipping, which calculates shipping costs. I wondered if anybody else had restored these same shipping options, since UPS is such a popular supplier, and the gem is the Ruby community's de facto default. Recently, I created Fork Freshness to answer the question, and I discovered that the answer is yes.
Here's the Fork Freshness report for Shopify/active_shipping. It links to all the project's most active and recent downstream forks.

Shopify created active_shipping, and they've since abandoned it, but 34 forks of the project continued development after Shopify archived it, and almost every single one of those 34 forks added UPS functionality back to the gem.
If I'd had Fork Freshness back when I was adding UPS functionality back to active_shipping, I wouldn't have needed to restore the same functionality that everybody else was already restoring. I could have just reviewed the existing forks and chosen the one that looked best. Likewise, if I had fixed any bugs, those bug fixes would not have been exclusive to my employer and our fork. Whichever fork we were using would have benefitted too.
This is what Fork Freshness is for.
Anyway, self-promotion aside, in order to create this project, I had to learn about analyzing git repos with Ruby, and discover some practical realities of the Ruby ecosystem on GitHub.
What I've Learned
First of all, I can't yet say for sure that most abandonware Ruby gems have forks that are still active. But I suspect it's the case. Fork Freshness has analyzed 5,762 git repos so far, but only 23 projects. However, of those 23 projects, 17 had forks that were more active than the original project. That's about 74%. Not all of those are Ruby projects, but most of them are.
This is a small sample size relative to the total overall volume of code on GitHub, and I only analyzed projects that I hoped had active downstream forks, so it's not a random sampling. But most of the time, when I hope that a "dead" project is really still alive downstream, it turns out to be true.
Anyway, projects that have active downstream forks typically only go two levels deep, in terms of how many forks also get forked. Usually people just fork the original, or at most, they fork another fork, but they don't typically get any more recursive than that.
I say "typically" because this did happen for a project called RailRoad. This is an unusual project. The deepest fork of RailRoad that I have found is a fork of a fork of a fork of a fork of a fork of an original project. It's six levels deep.
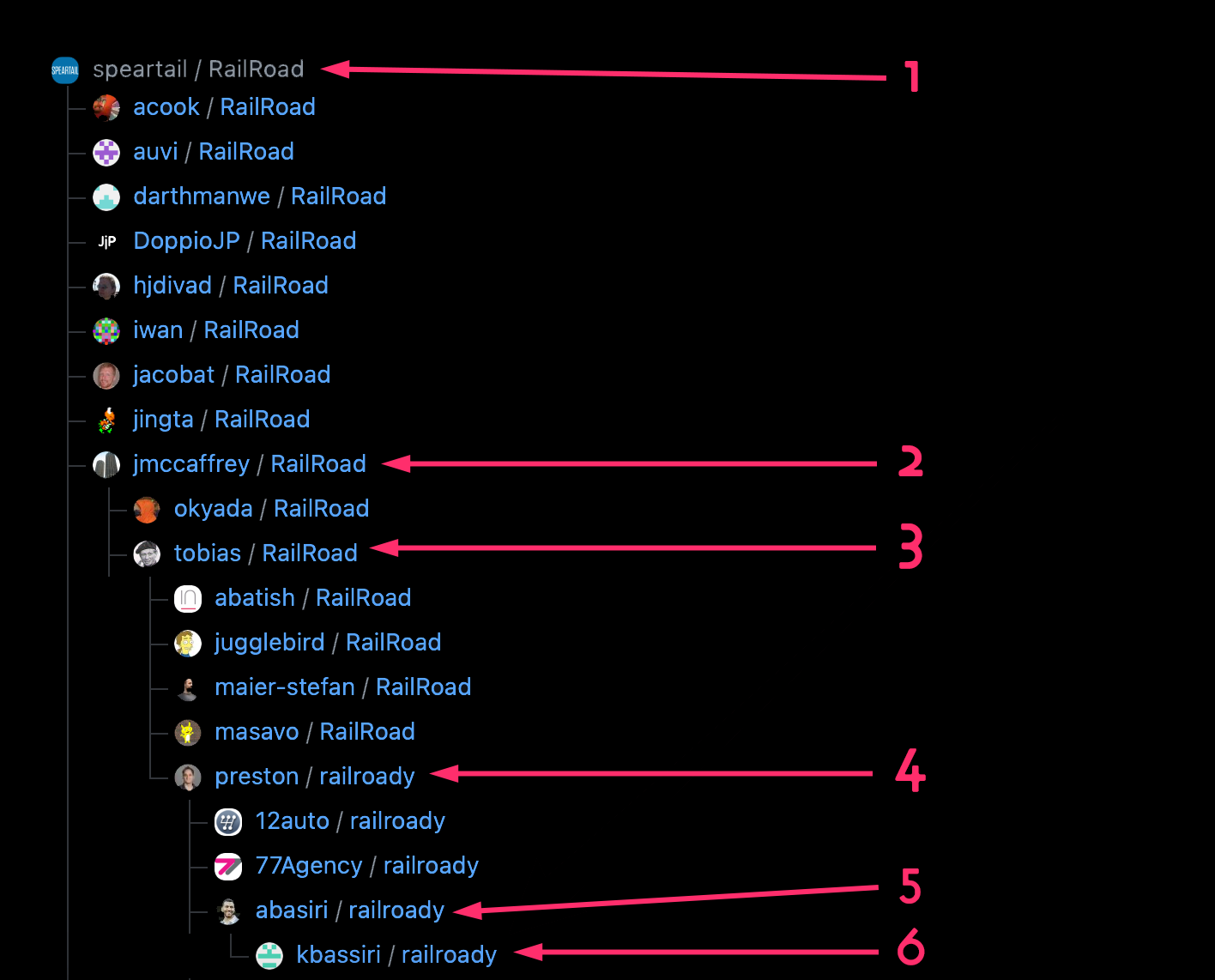
But even there, I have to caveat that "original project" part, because the README for the original project says this:
I (Peter Hoeg) am not trying to hijack Javier's project, but since he hasn't released any new versions since May '08, I figured I'd better put one out in order to make railroad work with rails v2.3.
This implies that back in 2009, when RailRoad's git history began, the real original project was some other project by someone called Javier. That other project might not even be on GitHub. If you were around and publishing open source in the late 00s, you know that GitHub was not yet the default that it is today. There were a lot of other options. So the real original project may be lost to the mists of time and/or SourceForge, but we can still say that this note in the README means that the deepest fork must technically be at least seven levels deep. So it's a fork of a fork of a fork of a fork of a fork of a fork of the original project.

At some point during this cascade of forks, this lineage changed names, from RailRoad to railroady. Just for context, RailRoad/railroady was/is a project for generating GraphViz .dot files with some version of Rails prior to 2.3. It was started at least 13 years ago. Fork Freshness can't even analyze it yet — maybe soon, if I change some of the code — because when I got started with Fork Freshness, I had no idea that a project's fork tree might have so many levels.
I think RailRoad/railroady represents both a problem of discoverability and of governance. The README frets about hijacking somebody else's project, but today I don't even know what that project was. Some of these forks probably exist because people disagreed about how the project should proceed, and others because people couldn't find the work that had already been done. Fork Freshness is only looking to solve the discoverability problem.
You can understand another discoverability problem by considering ClosureTree/with_advisory_lock. It's an outlier because most people who keep Ruby gems alive also continue using those gems on a regular basis. In this case, the maintainer is keeping this gem running, but he also said in a GitHub Issue that he doesn't use Rails any more. (It's a Rails gem.) And he said that back in 2017. He's still maintaining it, to his credit, but it's pretty reasonable to assume that some of the downstream forks might be more active than the original, even though the original isn't technically abandoned.
And this assumption would be correct. My UI for Fork Freshness doesn't currently show this, but underneath the hood, I can see in the Rails console that there are 15 people who have added commits to main or master branches for downstream forks of with_advisory_lock without ever merging those commits back upstream. (I might tweak the UI to show stuff like this in the future.) Only 15 people have ever contributed to the original repo, and to be clear, the number of downstream contributors is an additional 15 on top of that original 15. This means that as many people are keeping downstream forks alive as have ever contributed to the official, original project.
Since I'm trying to promote my new app, but I've just shown you two edge cases where it falters, I think I should show you a more typical situation where it shines. You've already seen how Fork Freshness revealed the many active downstream forks of Shopify/active_shipping, and made it easy to discover the common theme across those forks. Let's look at a similar gem: sferik/twitter.
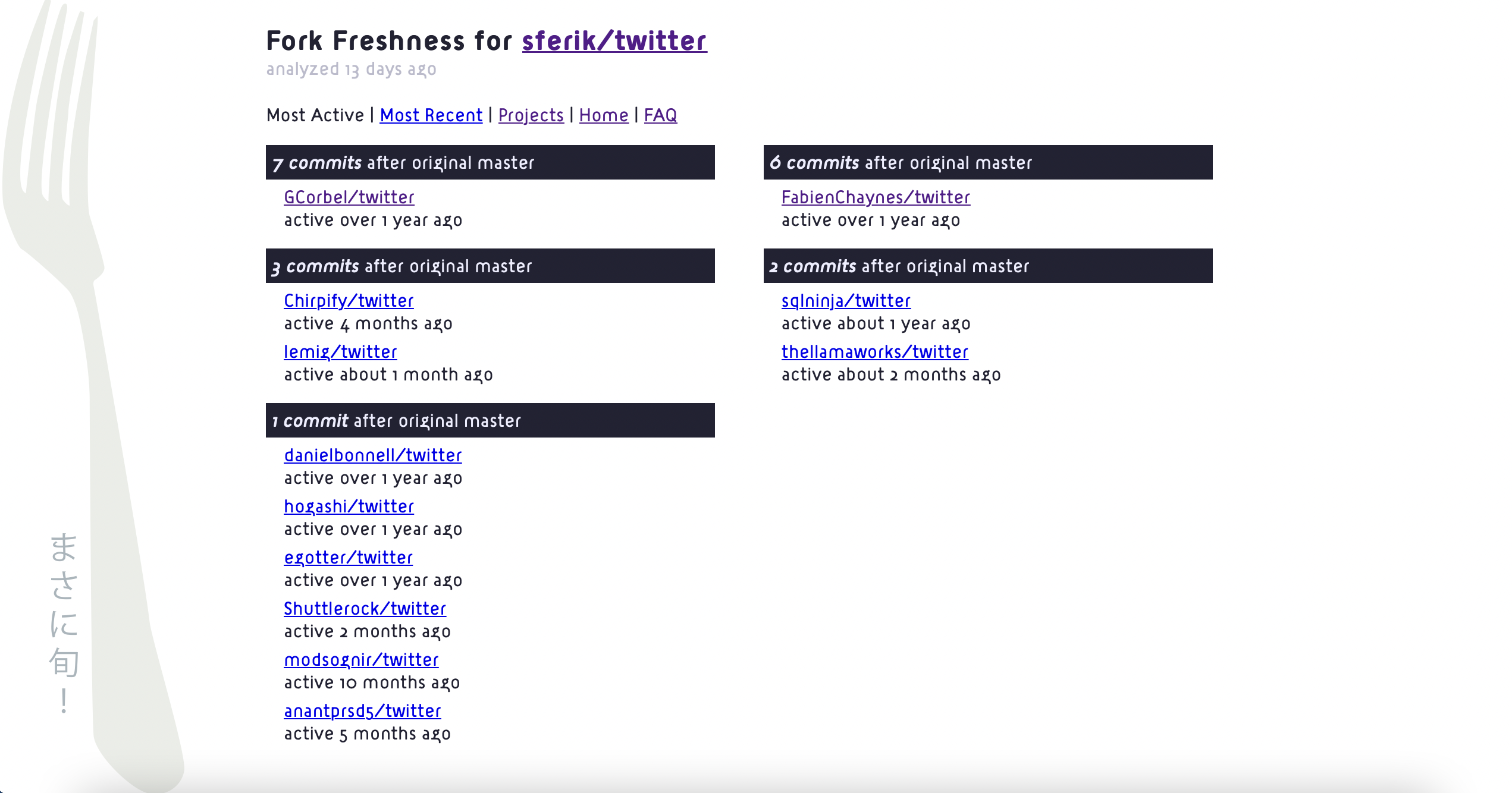
sferik/twitter is the Twitter gem. It hasn't been updated since February 2020, and that's not to shame the originator of the project. The first commit was on Dec 15, 2006. There's nothing wrong with moving on with your life after 15 years have gone by. Fork Freshness uses this gem internally, by the way, although I may switch to another fork now.
The gem has 12 active forks, which is to say 12 forks which have commits on main or master that are newer than the last commit on main or master for the original project. These downstream forks add support for new endpoints, update the OAuth implementation, and keep the gem up to date with new versions of Ruby. If I switch to one of these forks, it'll be for the sake of these features.
The Blind Spot
It's probably obvious at this point that GitHub has a blind spot. If you're considering using a project you found on GitHub, you want to see ongoing development in order to feel confident that you're not just taking on a liability. But a project has to remain useful to its originator in order for its ongoing development to be visible. If a project doesn't meet this rubric — which is ultimately a pretty random rubric, and was probably not chosen deliberately — then other random programmers become doomed to add the same exact UPS functionality back into the same exact abandoned gem, over and over again, with no knowledge of each other's efforts, because the project was too useful to truly die, yet not useful enough in the one very particular way which would cause GitHub to recognize its continued life.
This is where we get back into the self-promotion, because I created Fork Freshness to fix the blind spot.
For example, I recently used a Fork Freshness analysis to take my fork of a JavaScript blog plugin called eleventy-plugin-svg-contents and make it the most up-to-date fork. There was only one other active fork, but there were also a ton of Dependabot PRs against the original repo, which the creator of the project was ignoring. I cherry-picked commits from these PRs and the other active fork into my fork. It was a trivial effort, but it felt good to keep the project tidy and functioning.
This is what I hope people will do with Fork Freshness. To be clear, the main use case is just figuring out if a project is truly dead or not. If you're dealing with legacy code, or if you find a project that is useful but seems abandoned, you want to know if "dead" really means dead.
But imagine you love a project and its originator abandons it. This has caused lots of drama in the Node.js world, and it's disappointing for anyone. If you're one of the people who is keeping an abandoned project alive, Fork Freshness makes it really easy for you to find all the other people who are doing the same thing. Maybe in the future all 34 forks of active_shipping that are more active than the original project can join forces and create one canonical fork of active_shipping which everyone can use going forward.
The phrase "canonical fork" is a contradiction in the GitHub mental model, but it doesn't need to be. GitHub's originator bias isn't the only mental model git can support. Git's decentralized and distributed by design. It's pretty logical to say that the most important fork is the one that the community is still working on.
How Should We Visualize Projects?
GitHub recently released a project which explores new ways to visualize a code base. It's good to see this work happening, because I think it's a little overdue.
I have a pet theory that GitHub, despite the name, doesn't really model projects as hubs. It organizes them as lists. It may or may not be true in the deepest sense, but it's indisputably true of the Insights tab.
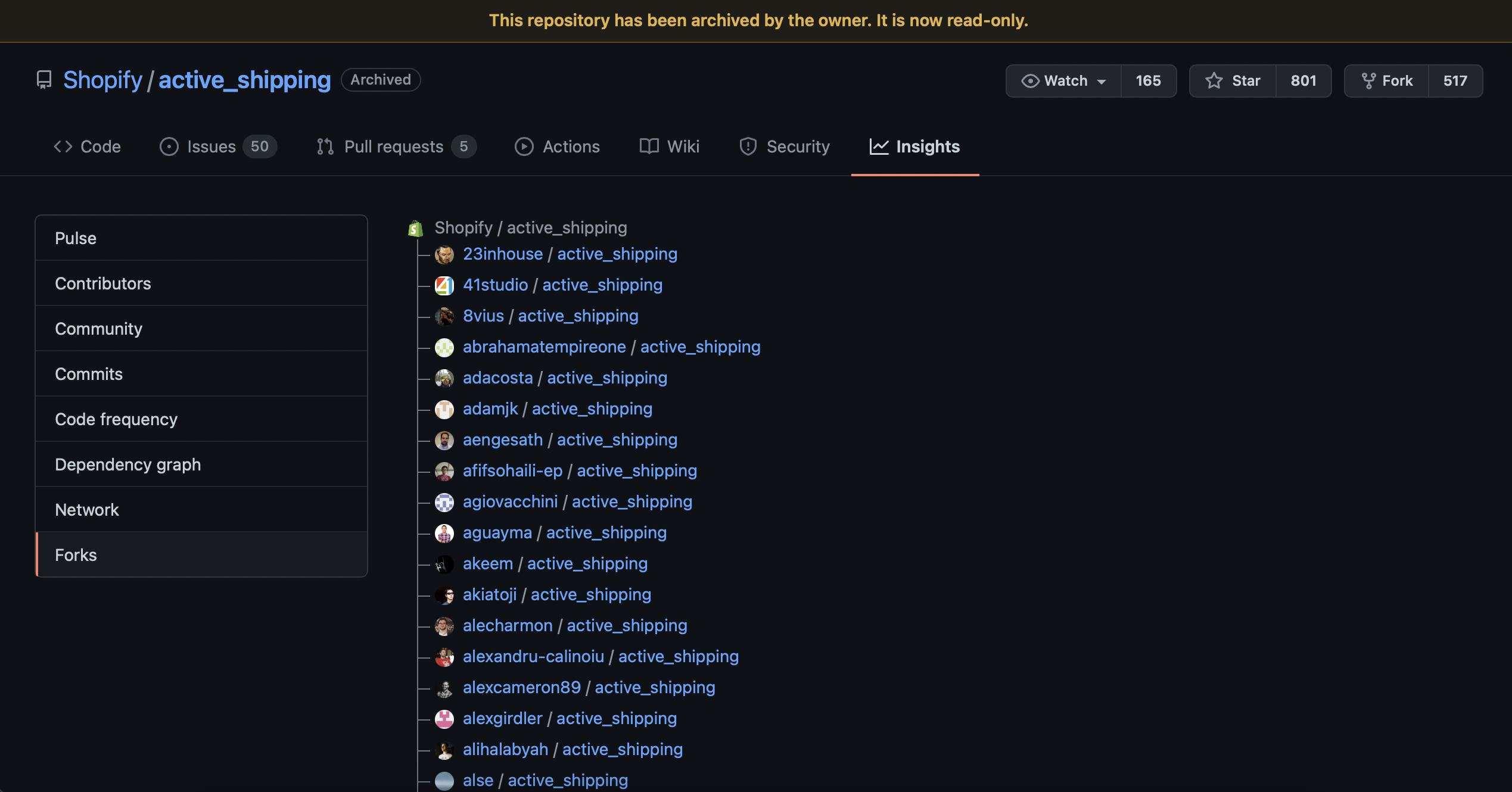
In this UI, the originating repo for a project is also the canonical example of that project, even after the originator abandons the project, and even if other forks continue to see ongoing development. The originator remains at the top of the list; all the other forks are just alphabetized.
I think GitHub made a mistake in organizing all the repos in a project as a list. This is kind of a neglected corner of the UI. Treating the original as a hub with many spokes, like the name suggests, would make social coding easier. It's not about the originator; it's about the community. If a spoke of the hub is more active than the hub itself, just highlight that spoke.
For instance, this is a force-directed graph which represents the active forks of lardawge/carrierwave_backgrounder using a modest visualization experiment which may show up later on Fork Freshness:
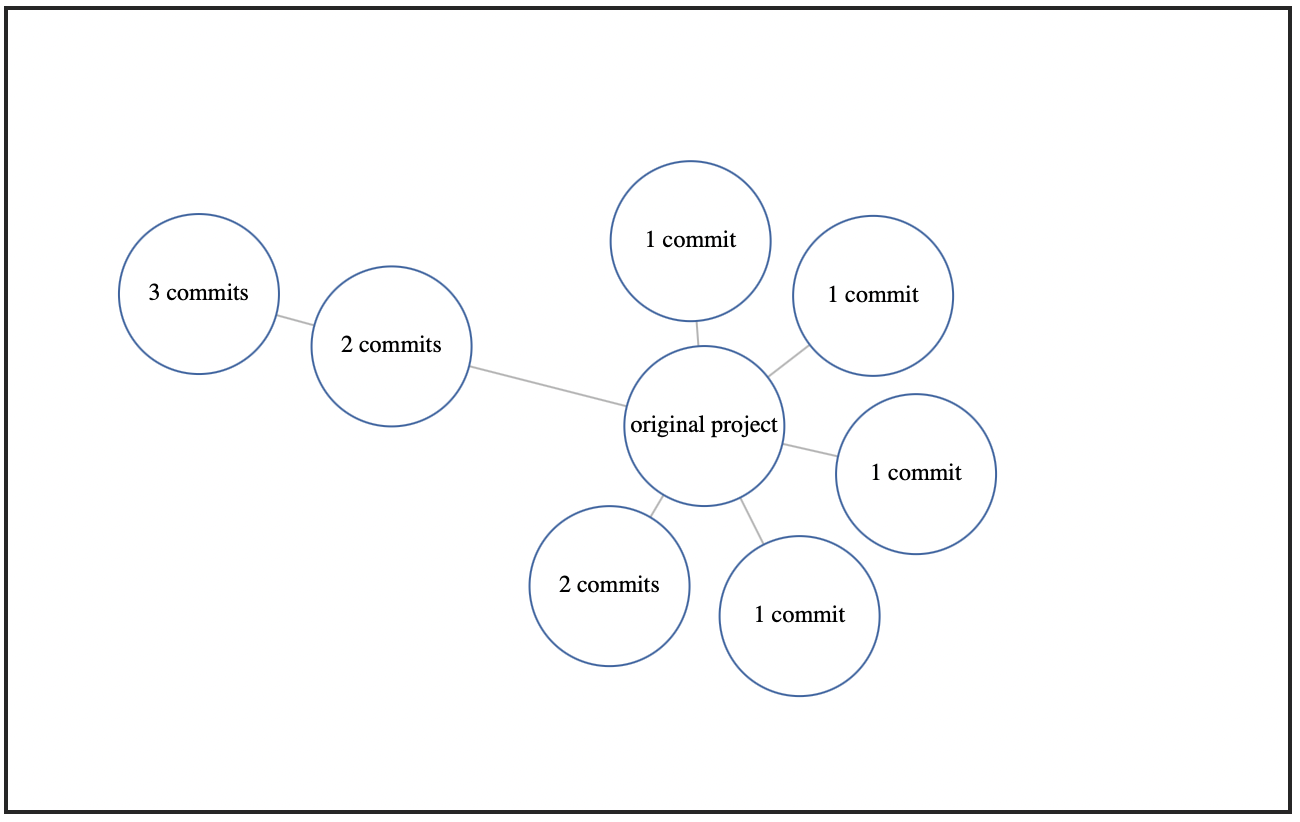
By looking at this graph, you can see that the fork of carrierwave_backgrounder which is three commits ahead of the original project was forked from another fork which was already two commits ahead. But most of the forks have been forked from the original project, which means that the original project is the hub in this little cluster of git repos. You could almost call it the git hub.
I haven't yet applied this code to the RailRoad/railroady family of projects, which I discussed above, but it's probably the only way to look at that set of projects and understand what you're seeing. This hub/spoke mental model for understanding the relationships between different variants of the same code base has some advantages over a simple list. It's clearer, it's more accurate, it exposes more information, and it's in the freaking name.
Either way, there's my soapbox. Let's talk about how Fork Freshness works.
How It Works: UI
Fork Freshness is a Rails app, but it has a read-only web site. You cannot use the Fork Freshness web site to request an analysis; you have to instead tweet the @ForkFreshness Twitter account with the GitHub URL for the project you want it to analyze.
I did this for three reasons. First, I want all the data this app obtains to be public. It's an app for analyzing open source projects, so its analyses should be shared with everybody.
Second, every Rails app ends up with a User object the size of a skyscraper. The official name for this antipattern is "God Object," but you can understand the problem more clearly if you think of it as a Godzilla Object instead. I was tired enough of battling these godforsaken kaiju that I wanted to see how far I could get building a Rails app without any User model at all.

In practice, of course, the AnalysisRequest model — which essentially represents an incoming tweet — has almost become the Godzilla Object instead. My theory now is that whichever ActiveRecord model is closest to the UI will grow huge as it comes to incorporate a comprehensive catalog of user interactions. It's an interesting question, but it's also a topic for another time.
My third reason for having no User model and making Twitter the UI was that Fork Freshness performs an analysis which is not a good fit for the twitchy, near-instantaneous UI rhythm of web sites and apps. Instead, it's a perfect fit for the rhythm of asynchronous communication. It takes time to clone over a thousand repos and analyze their respective histories, and an app that provides deep insight into a big decision can take a little more time than an app that merely satisfies some inane reflex. Reflex is the default, maybe even the only category that most people even recognize, but it's a counterproductive default. If more apps revolved around deep insight and asynchronous communication, we'd probably uncover entire new categories of useful work for computers to do.
Dependabot is a perfect example of an app which runs asynchronously and does deeper work than merely satisfying a meaningless reflex. However, like anything in tech, it has tradeoffs.
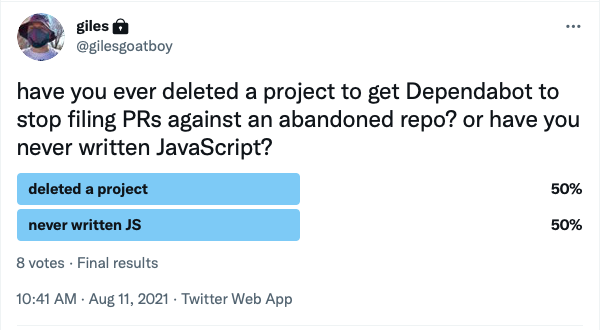
Anyway, with a Twitter chatbot being the effective UI, Fork Freshness has a Sidekiq periodic job running which checks Twitter. It does this using the Twitter gem, which I discussed above. When you tweet at @ForkFreshness, it checks your tweet for a GitHub URL. If there's already an analysis, it will just tweet back the link to that analysis, but otherwise, it'll tell you that an analysis is coming up, get started on that analysis, and then tweet the link to you when it completes.
How It Works: Git Analysis
When Fork Freshness does a new analysis, it gets the list of forks to clone via GitHub's GraphQL API. I have to admit that Fork Freshness works by going through this list and cloning every single project. I would prefer this part to work differently, although writing the actual git analysis code was a lot of fun.
I tried to calculate freshness from information in GitHub's GraphQL API. One promising option seemed to be pushedAt, on the API's Repository object. pushedAt tells you the date and time of the latest push, which seemed super relevant. What I found, though, was that pushedAt counts commits in pull requests as well as commits that have actually been merged into the project, and Dependabot continues submitting pull requests to otherwise-dormant projects for months or even years after those projects have been abandoned. This means that dormant projects can still have very recent values for pushedAt, but those "recent commits" are on random PR branches that no human being has ever set eyes on. So Fork Freshness doesn't use pushedAt.
If Fork Freshness did use pushedAt, it would be a lot faster. active-forks is a similar app to Fork Freshness. It is much faster, probably by orders of magnitude, and also has a much smaller code base, definitely by orders of magnitude. active-forks runs on the GitHub REST API. If active-forks says a repo had its last push on X date, it means that the GitHub REST API returned that date for its pushed_at attribute. GitHub's REST docs are a little less detailed than its GraphQL docs, but pushed_at appears to be the same thing as the pushedAt that the GitHub GraphQL API returns.
Obviously, I prefer my own app, because Dependabot adds noise to pushed_at/pushedAt, and any unmerged pull requests from human beings also make pushed_at/pushedAt noisy. active-forks also doesn't seem to have a concept equivalent to the subsequent commits idea in Fork Freshness. Subsequent commits represents how many commits have occurred after the last commit on the originating repo's main or master branch. It's a measure of ongoing development, and I think that's a useful metric. But to be fair, the deeper analysis you get with Fork Freshness is also slower. If you're in a hurry, you might get more mileage out of active-forks.
The big speed difference comes from the fact that active-forks grabs the latest info from the GitHub REST API and presents it to you almost instantly. By contrast, Fork Freshness grabs a list of projects from the GitHub GraphQL API, clones every single one of these projects, and then analyzes them using the Rugged gem, which is a thin wrapper around libgit2.
Caution makes Fork Freshness slow also. Anecdotally, from cloning many projects many times in developing Fork Freshness, it appears to me that GitHub may have rate limits on cloning. This perception may just be due to bugs in my own software, especially earlier in development; however, it's impossible to say for sure. GitHub clearly and explicitly documents rate limits for its REST and GraphQL APIs, but the only official information I could find on this indicates that cloning rate limits may exist, and may change at any moment. So Fork Freshness clones slowly and gently in order to avoid angering GitHub.
Once the cloning is out of the way, analyzing git with the Rugged gem is really easy. Rugged/libgit2 thinks of going through a commit history in terms of walking a tree, like a tree-walking parser. So you walk the commit tree, ignoring commits that aren't on your preferred branch(es), and you collect metadata as you go. Fork Freshness collects metadata organized around these questions: does this repo have commits that happened after the last commit on the original project's repo, and if so, how many, and when did they happen?
Fork Freshness keeps the original repo on the filesystem throughout its analysis, for comparison purposes, but deletes every fork immediately after analyzing it and comparing it to the original, and deletes the original last of all. For each fork of a given project, Fork Freshness captures the most recent commit date, calculates the number of subsequent commits — which is to say, how many new commits have happened since the originating repo went dark — and then, in its UI, sorts projects by how active they are and/or by how recent their activity was.
To avoid a combinatoric explosion and much noisier data, the app only looks at branches called main or master. This means that if your fork has useful topic branches which you developed after the original project was abandoned, Fork Freshness will only notice after you merge those topic branches. And this means that the Fork Freshness probably underestimates the number of people keeping various projects alive. If you made a fork for your company but you're hoping that one day, you'll find out that the original is still alive, then you might not be committing to main.
Further Exploring
I've only scratched the surface here of what you can learn about the lifespans of GitHub projects and/or Ruby gems. If you want to know more, the GitHub GraphQL API and the RubyGems API are both extremely useful. You can also check a given Gemfile against Bundler's update and outdated commands, or use the bundleup gem for a nicer command-line interface.
If you want to automate your own git analyses, the git gem is fine to start with, but you'll want the Rugged gem the moment performance starts to matter. And speaking of only scratching the surface, James Coglan wrote an excellent book where he guides you through re-implementing git in Ruby, although I have to admit I have not yet finished reading it. (It's very comprehensive.)
If you're interested in using tools like these to keep your dependencies healthy, the Rust ecosystem has a somewhat related project called lib.rs/about which calculates freshness in a different way:
Versions are considered out of date not merely when they're less than the latest, but when more than half of users of that crate uses a newer version.
(A crate in Rust is equivalent to a gem in Ruby.)
Fork Freshness is of course a new project, but it has already analyzed thousands of git repos. The initial results make it look very, very likely that there are a lot of "dead" projects out there which are, in fact, quite healthy and alive downstream. Open source has done great things for me in my life, so my hope is that Fork Freshness will give back to open source devs, both by reducing the number of times they need to restore UPS functionality to active_shipping in particular, and by reducing this whole category of repetition in general.
So thanks for reading this overview of project lifespans and introduction to my new app. As a token of my gratitude, please enjoy this picture of a hippo cart. But do not attempt this under any circumstances. Hippos are very dangerous.

